Welcome 20% less memory usage for G1 remembered sets - Prune collection set candidates early
For a long time remembered sets have been an issue with the G1 garbage collector. Recently there has been an interesting, small change [7] with quite a positive impact in this area that I would like to highlight a bit.
Introduction
The G1 garbage collector uses, like any other incremental collector, remembered sets to store the locations of references into the areas to copy during garbage collection. After all, if you copy an object, the references to that object need to be changed to the new location, otherwise your application will crash on the next access. The remembered sets is that data structure that stores these locations.
G1 stores remembered sets on a per-region basis to enable per-region evacuation. Every time the application installs a reference between G1 regions [0] that may be evacuated in the future, a small bit of code is executed that adds that location to the remembered set for the region that reference points to.
Problem
So, how much memory can these remembered sets take? (Un-)Surprisingly, quite a bit.
For demonstration purposes this post uses BigRamTester [2] to demonstrate exactly that. This simple application simulates an “in-memory database”, a large hash table where items are added and removed in LRU fashion all the time. So the Java heap will be full of references pointing all over the place to these elements, stressing remembered sets and creating large remembered sets.
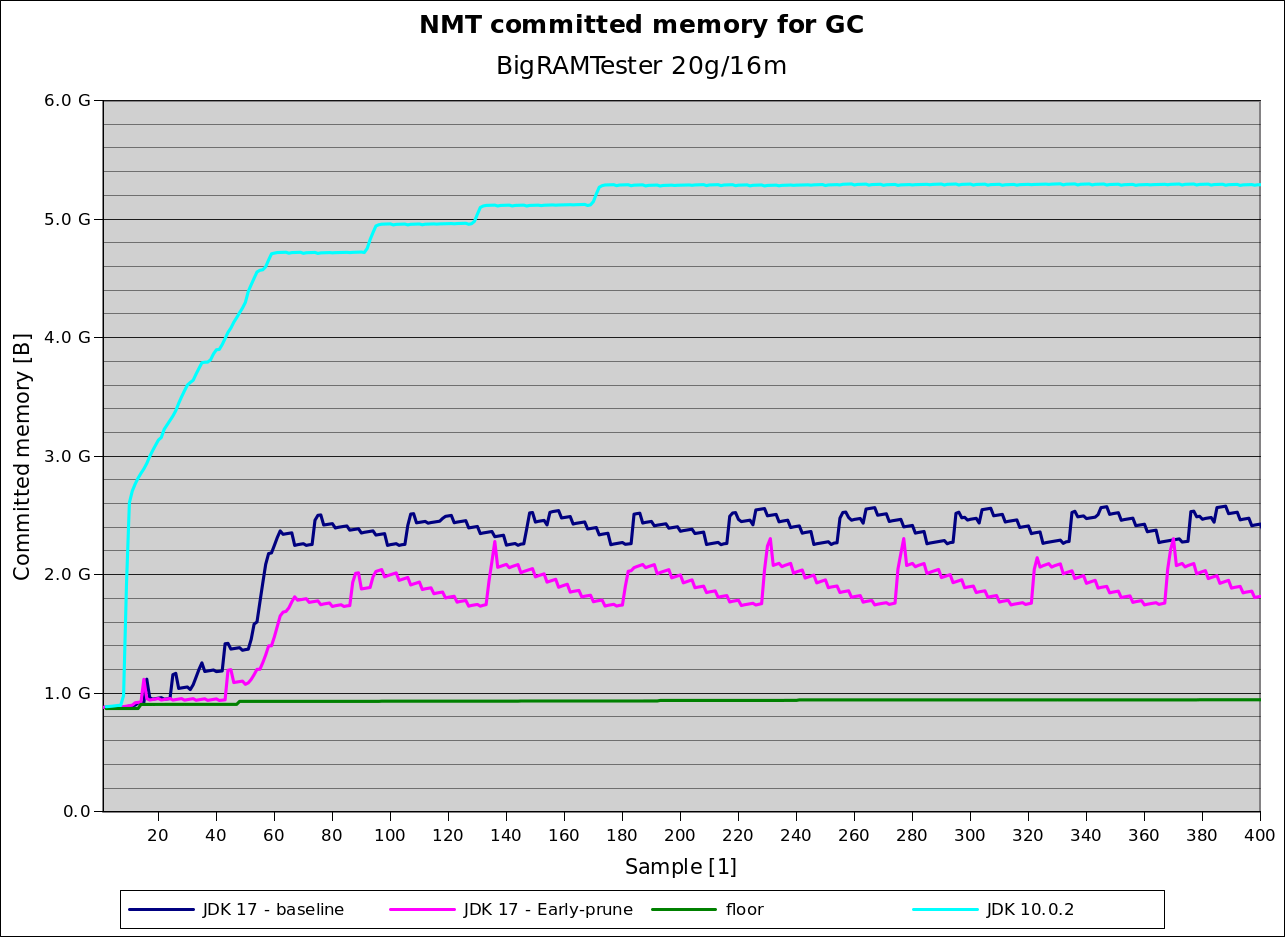
The following graph shows committed memory for the “GC” component as calculated by the Java VM’s Native Memory Tracking (NMT) facility [1] for BigRamTester [2] taken every second on a 20GB Java heap. This results in choosing 16 MB regions used with OpenJDK on a recent tip [3].
The exact options are
$ java -XX:+UseLargePages -XX:+AlwaysPreTouch -Xmx20g -Xms20g -XX:MaxGCPauseMillis=500 -XX:+AlwaysPreTouch -XX:NativeMemoryTracking=summary BigRamTester 900
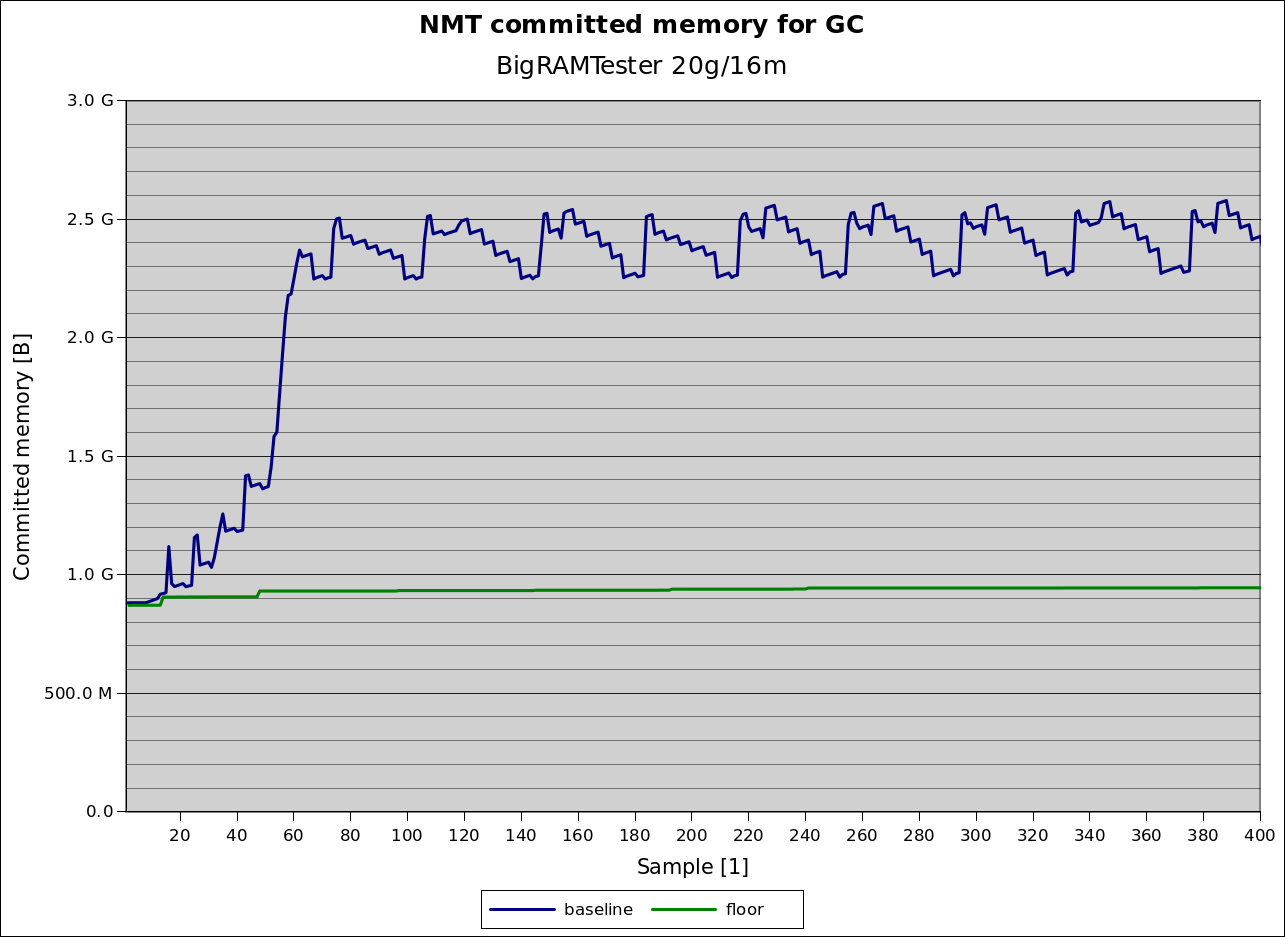
In addition to the memory consumption (“baseline”) in dark blue, the graph also shows a “floor” (green) that shows the amount of memory used by the GC component not by the remembered set. Overall, in this case G1’s remembered set takes at most 1.6 GB, around 8% of the java heap. More than the rest of what G1 needs for operation, around 900 MB
Whoopsie.
Background
G1 has two alternating operating phases, the young-only and the space reclamation phase. During the young only phase G1 fills up the Java heap in the old generation gradually. At some point G1 decides that it is time to collect space in the old generation, and starts to look for free space there in the background. After completion of this so-called marking, G1 selects regions, the collection set candidates [4], for eventual space reclamation. Before it can do so, it needs to build remembered sets for these candidate regions, as G1 did not maintain them during the young-only phase (it was not going to reclaim space in the old generation anyway, so why maintain them? [7]).
As soon as the remembered sets are complete, G1 moves to the space reclamation phase, collecting and reclaiming space in a few old generation regions from the collection set candidates at every garbage collection. The space reclamation phase either ends when either there are no more regions in the candidate collection set, or the space left to reclaim is less than 5% than the current heap size [6] after a garbage collection pause in that phase.
The reason for the second condition is that the last few regions in the candidate list tend to take relatively long to collect. G1 sorts candidates for efficiency, a metric considering both how much empty space a region will yield, and how hard they are to collect, i.e. basically how many remembered set entries it contains. G1 collects the most space yielding and easy to collect regions first. So this rule filters out regions that would cause too long pause times, sacrificing memory for latency.
The change
This time of application of that latter condition about not evacuating inefficient regions is what can be improved: it means that G1 effectively maintains remembered sets for regions that it will never ever reclaim space from. Even worse, these remembered sets are maintained until the end of the space reclamation phase. This can lead to the surprising situation, that while collecting these regions, remembered set usage rises although the number of regions where they are maintained decreases. This effect can be observed in the memory usage graph above too: after every first hump of remembered set memory usage shows where remembered sets are built up, but there is a second one that is even higher than the first one before finally going down.
So the straightforward solution for this problem would be applying that rule after the candidate selection, and before building the remembered sets.
There is a caveat with that: this might remove all regions from the collection set candidate list, resulting in no or very little reclamation progress for that space reclamation phase. This is undesirable, because G1 just spent all that marking effort for (almost) nothing. For this reason, and also to simulate that in the original heuristics that rule has been applied at the end of a collection, G1 keeps at least a set amount of regions based on some expected amount of mixed collections in that space reclamation phase.
Rerunning BigRamTester another time with this patch applied, shows the following memory consumption graph (in pink):
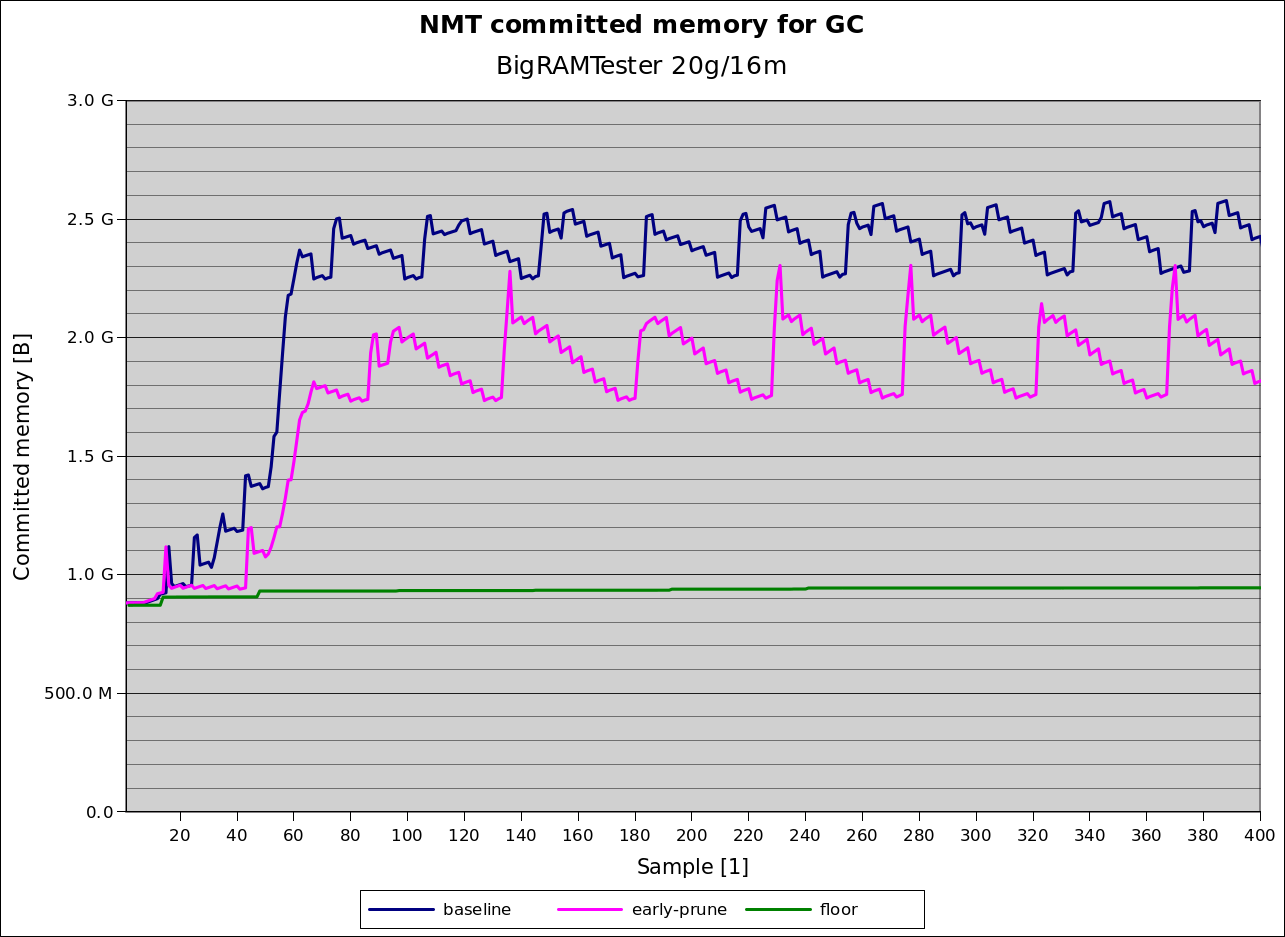
A reduction of remembered set peak-to-peak memory consumption by 250-300 MB - the promised 20%. At least for this type of application :)
Actually it could be much more, but that has to do with how G1 currently manages the remembered set data structure. This is an issue to be solved another time.
See you next time,
Thomas
P.S.: This change is a part of some longer spanning effort to reduce remembered set memory consumption.
For comparison, here is a graph showing memory consumption of the GC component for the same benchmark in JDK 10.0.2 (cyan) including the ones shown above for comparison. JDK 8 and JDK 9 are at least worse than that, but due to a bug in remembered set NMT accounting [8] it is harder to get the exact numbers.