Card Table Card Size Shenanigans
JDK 18 introduces configurable card table card sizes with JDK-8272773. This post tries to show you what the card table is, and why you might want to play around with this new option.
Introduction and Background
When the garbage collector moves an object in the pause, it needs to adjust any references to that object to point to the new location.
The naive and very slow approach would iterate over all of the areas of the Java heap that are not evacuated to find them.
The card table speeds up finding these references: it is a side data structure where every element corresponds to a small part of the Java heap. These elements are called cards. Now, if the Java application (the mutator) modifies a reference, the VM executes code that sets the card which contains the reference to a special value. In the garbage collection pause the collector then searches the card table (which is much smaller than the Java heap, and much faster to traverse) for these special values. If such a special value found, the collector searches the corresponding Java heap area for references into the evacuated regions. Such a data structure is also commonly called a remembered set.
This paper explains this technique in more detail.
All Hotspot stop-the-world collectors Serial, Parallel and G1 GC use the card table in some form. Serial and Parallel GC almost exactly use it as described above and in the paper.
Since this post uses G1 to discuss the impact of this change, we need some more background on how it uses the card table: in G1, the card table data structure exists, but it is used quite differently.
The reason is that G1 allows independent evacuation of any heap region, so every region needs its own remembered set. This is an additional set of cards per region, every card indicating a location where there might be a reference into that region.
-
While the mutator runs, in G1 the card table only temporarily stores locations of potential references: in addition to marking the corresponding card, the mutator thread also stores that change into a thread-local log buffer if that card has not been marked before, that are periodically processed by concurrent refinement background threads. This concurrent refinement clears the mark on the card table (which in the meantime acts as a filter for additional refinement requests of the same card), scans the area corresponding to the card for references and populates the appropriate remembered sets.
-
In the garbage collection pause, the card table data structure is reused to first determine a combined remembered set for the whole collection set (the
Merge Heap Rootsphase atgc+phases=debuglog level), then scanned for references into that collection set similar to the other collectors (in theScan Heap Rootsphase).At the end of a collection, G1 needs to prepare the card table for use in the mutator phase (in the
Clear Logged CardsandRedirty Logged Cardsphases).
The Change
Until now, the size of the area a card covers has been fixed to 512 bytes. This size has been a tradeoff between the size of the card table (one byte per card, resulting in a memory usage of about 0.2% of Java heap size) and how long it takes to find the reference within that area during garbage collection.
With JDK 18 you can select its value using the -XX:GCCardSizeInBytes from one of 128, 256, 512 (default) and 1024 (the last is 64 bit only).
Impact Discussion
The original contributor, V. Chand, saw SPECjbb2015 critical-jOPS (latency) score improvements in G1 when increasing this value to 1024. In this case, the improvement is caused by significant reduction of the Clear Logged Cards phase (at the time called Clear Card Table) due to a combination of the hardware, and the benchmark used.
SPECjbb2015 is very low on actual references between old and young generation, in a typical tuned setting only Young GCs are performed, with a huge young generation (like 90% of the heap). So the Clear Logged Cards phase that prepares the card table for the next mutator phase and is proportional to the young generation size takes fairly long. Halving the card table by doubling the card table card size halves that work, showing the observed impact on the pause time and the benchmark scores. This effect can be seen on the spreadsheet attached to the CR.
A potentially more interesting and more common case is decreasing card table size: if the Scan Heap Roots time of an application takes a large part of the garbage collection time, and the references are fairly clumped together, there may be a significant performance gain by using smaller cards. Obviously this gains may be offset by more (smaller) cards to scan, the added memory usage as the card table grows, but overall a net win.
One particular application of that kind is BigRAMTester (from JDK-8152438 - an LRU managed object cache - shows this exact behavior:
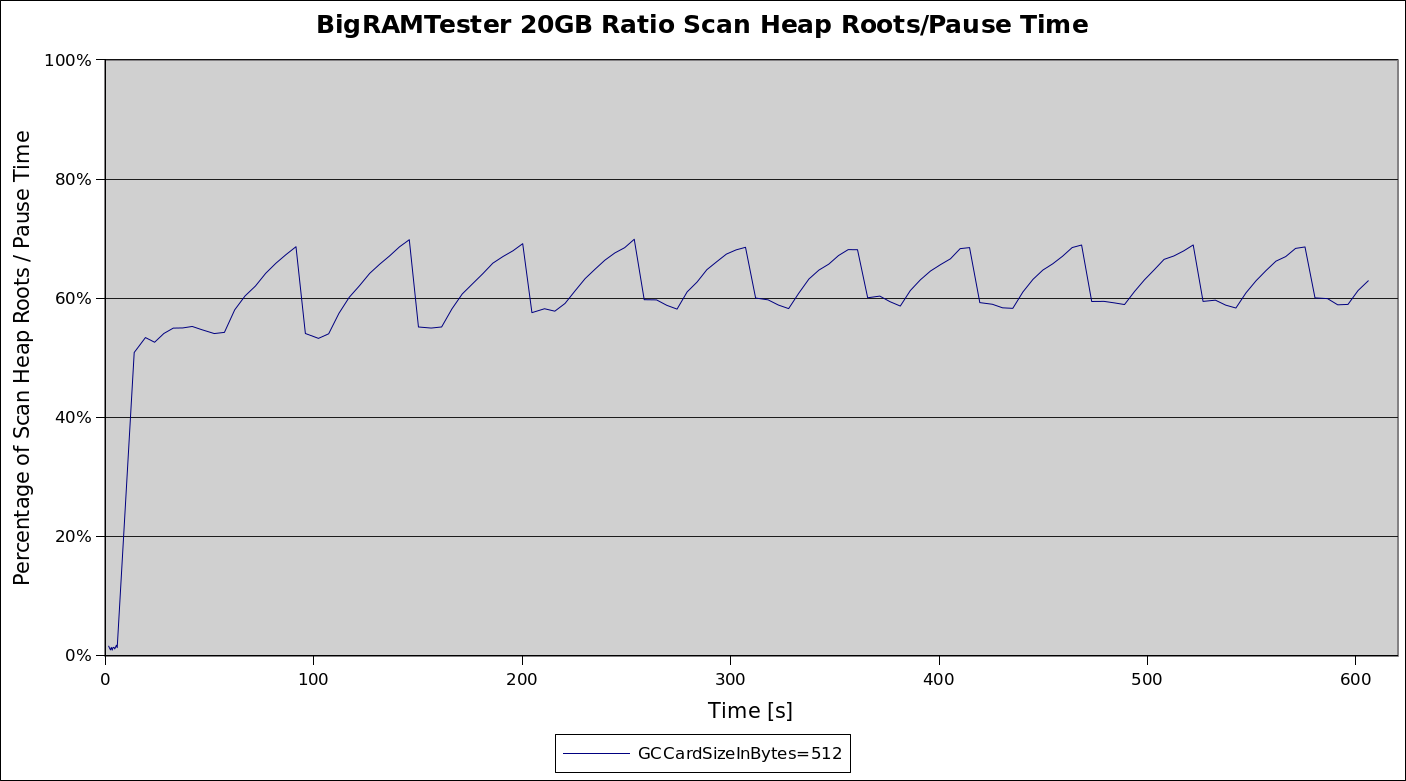
Around 60-70% of garbage collection pause time is spent on looking through cards for references, finding not a lot as the next graph that shows the number of references (“roots”, as per Found Roots metric in the logs) per kB scanned during the Scan Heap Roots phase (as per Scanned Cards metric in the logs).
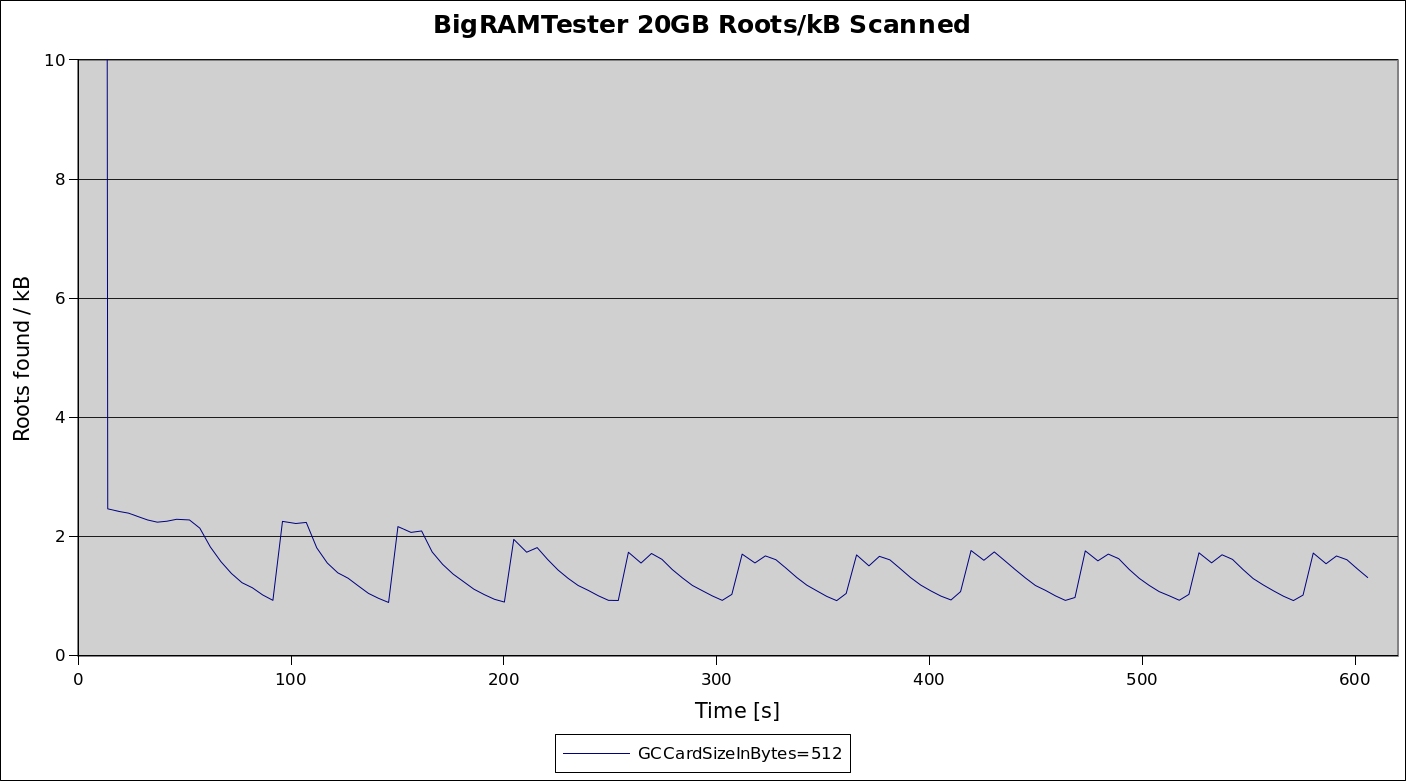
So on average, including all cards, whether completely empty or not, there are only one to two roots per card in the card table. Graphing the same run with available card sizes from 128 to 1024 shows that by changing card size we can improve this ratio quit a bit:
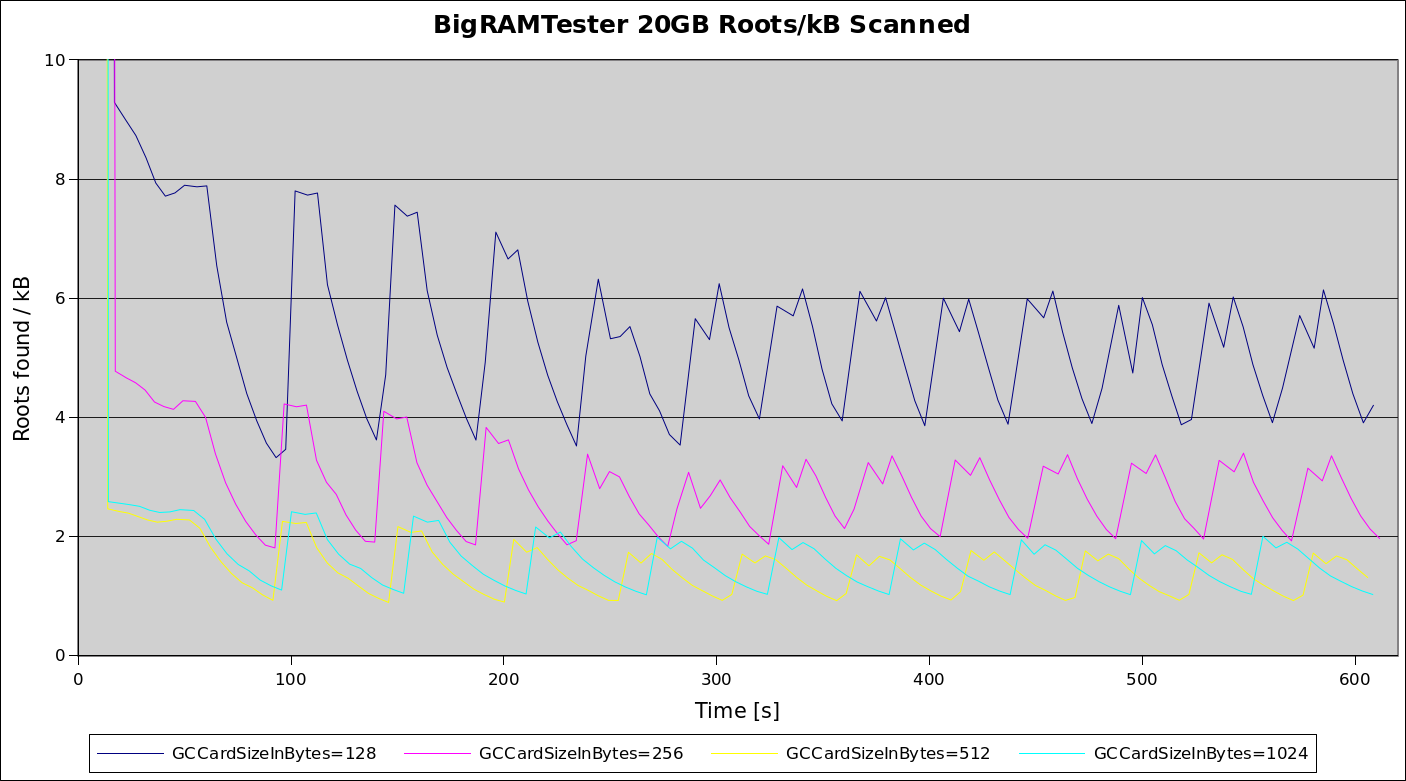
In this application, decreasing card size proportionally increases the amount of roots per memory unit scanned, i.e. less work. This indicates that having more exact locations may decrease the Scan Heap Roots phase quite a bit. The hypothesis here is that the roots are spaced fairly wide apart (the ratio of roots/card is fairly similar), so that even increasing the card size to 1024 bytes does not improve the amount of roots per kB scanned too much.
The next figure shows the impact of card sizes on the pause time in this application:
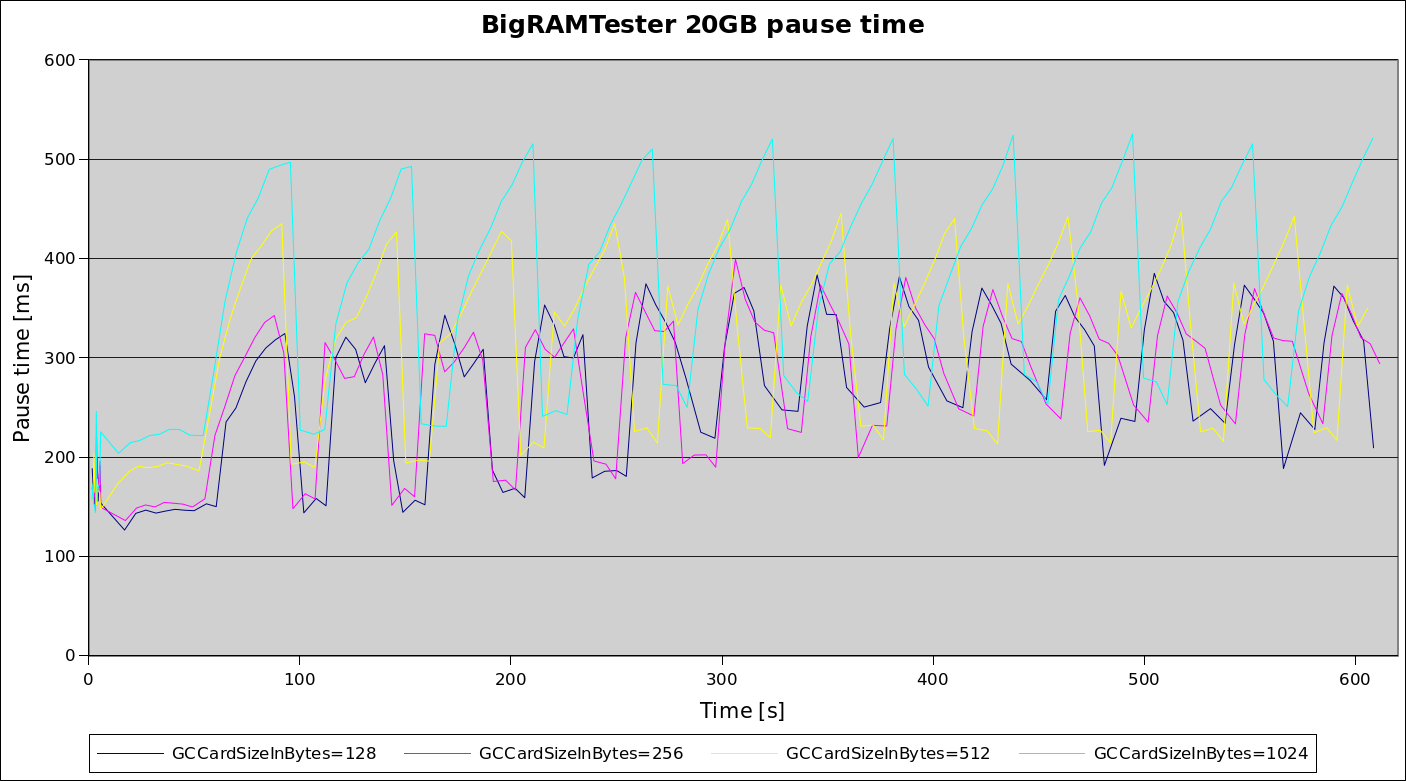
Pause time increases for a card size of 1024 (cyan line) - there is just so much more memory to look through than in other cases, outweighing all other benefits. Pause times for card sizes of 128 (blue) and 256 (purple) are basically tied: while the Scan Heap Roots phase is shorter the smaller the card size is, other phases of the garbage collection (mainly Merge Heap Roots, but also Clear Logged Cards) tend to get proportionally longer, cancelling out each other.
For this application, a card size of 256 bytes seems optimal performing no other option tuning: pause times are as good as with 128 bytes cards at half the memory usage than with 256 bytes for the card table, and around 20% better than with the default 512 bytes (yellow).
If you can afford the additional 0.2% of Java heap memory usage when using a card table size of 256, this seems a worthwhile tradeoff in this application.
Summary
There is a new option -XX:GCCardSizeInBytes. It modifies the granularity remembered sets are tracked for Serial, Parallel and G1 GC. This changes the amount of work needed for various garbage collection phases; this post shows that depending on the application, this may change pause times significantly, sometimes good, sometimes bad.
We would be happy to hear your experience tuning with the card sizes though, please send comments to me, hotspot-gc-use@openjdk.java.net or hotspot-gc-dev@openjdk.java.net.
That’s all folks,
Thomas