JDK 22 G1/Parallel/Serial GC changes
Another JDK release, another version of a post in this series: this time JDK 22 GA is almost here and so I am going to entertain you with latest changes for the stop-the-world garbage collectors for OpenJDK for that release. ;)
Overall I think this release provides fairly significant changes in the stop-the-world collector area like JEP 423: Region Pinning for G1. Next to the actual change in functionality it required some at least technically interesting changes under the hood. Also both Serial and Parallel GC young collection got performance improvements.
The full list of changes for the entire Hotspot GC subcomponent for JDK 22 is here, showing around 230 changes in total being resolved or closed at the time of writing. This does not completely reflect changes on garbage collectors some of the significant ones were attributed to other subsystems but had significant impact on garbage collection pause times.
Following is the usual run-down of interesting changes for the Hotspot stop-the-world collectors in JDK 22:
Parallel GC
-
Finding old-to-young references is a significant task during generational garbage collection. Parallel (and Serial) GC use a card table for this purpose. First, mutators mark card table entries that potentially contain references as “dirty”. Then, during the pause the algorithm scans the card table for these dirty marks, and looks through the objects indicated by these marks given they potentially have old-to-young references.
Parallel GC (as the name implies) uses multiple parallel threads when looking through the typically large card table. The work distribution mechanism for card table scanning partitions the heap into 64kB chunks. Any card marked objects starting in that area are owned by that thread for processing.
JDK-8310031 implements two optimizations that lead to better work distribution and better performance:
- contents of large object arrays are split across partitions, now not only the thread that owns a large object array looks for old-to-young references in that object. This could previously lead to a single thread walking through a GBs large object by itself. Although there is some additional work distribution mechanism based on work stealing from queues following the card scanning, this stealing is relatively expensive compared to just having multiple threads looking at parts of that object in the first place.
- that single owner thread always looked through all elements of the array, although the dirty cards indicated the interesting locations already. So the processing thread often looked through many references which were known to not contain any old-to-young references. This changed to a thread only processing the parts of the large object array that were marked dirty.
The old behavior resulted in inverse thread scaling in some cases, and very long pauses compared to for example the G1 collector.
-
Another performance issue with Parallel GC related to large array objects in the Java heap has also been fixed. Parallel GC now uses the same exponential backskip in the block offset table for finding object starts as the other collectors, speeding up this process and overall pause time.
The block offset table solves the problem of finding the object start preceeding a card in the card table. One application is during above mentioned card scanning where the garbage collector needs to quickly find the start of the Java object either starting at or reaching into that particular card to start decoding that object (looking for references) properly.
For every card (that typically represents 512 bytes of the Java heap) there is a block offset table (BOT) entry. That entry stores either how many words back from the heap address corresponding to this card the object reaching into this card starts, or that in the preceeding card there is no object start and the algorithm needs to look at the previous BOT entry for more information. The change JDK-8321013 introduces changes this backskip value from just “look at the previous card” to the number of cards to go back used as exponent of base two.
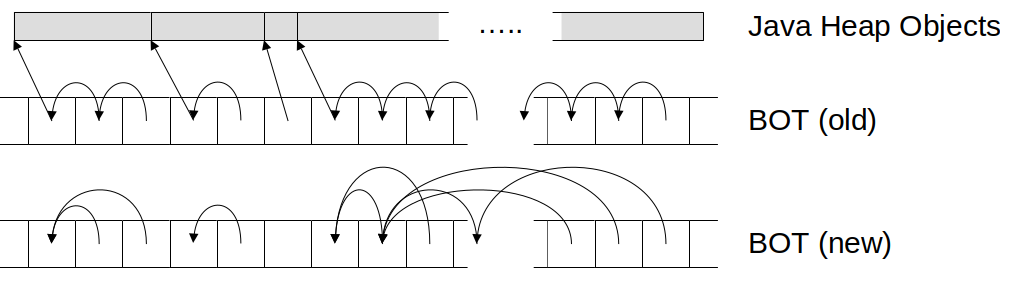
The figure above tries to depict that: the Java Heap Objects at the top gives an example for how some Java objects could be arranged in the Java heap; the middle figure shows the BOT with its entries and what they each refer to. Some of them refer to object starts in the heap, others that do not contain an object start refer to the previous BOT entry (the backskip value). The bottom figure shows the backskip value with the new BOT encoding (only showing backskip references) where backskip values do not necessarily refer to the previous BOT entry, but some entry far before the current one within the object. This is fairly obvious for the large Java object on the far right, where walking from an address from the end of that object to the start could take many steps, while with the new encoding the garbage collection algorithm only needs a few.
This dramatically reduces the amount of memory accesses when trying to find object starts for larger objects and improves performance.
Serial GC
-
JDK-8319373 optimizes the card-scanning code (finding dirty cards) in Serial GC based on the new Parallel GC code added in JDK-8310031. This also significantly reduces young collection time if the dirty cards are rare.
-
A lot of effort has been spent to clean up Serial GC code, removing dead code and abstractions for when the same code has been shared by the Concurrent Mark Sweep collector removed in JDK 14/JEP 363.
G1 GC
Here are the JDK 22 user facing changes for G1:
-
G1 now (JDK-8140326) reclaims regions that failed evacuation in the next garbage collection of any type. This improves the resilience of the G1 collector against having its old generation swamped with evacuation failed regions.
The main use case is region pinning: trying to evacuate a pinned region causes an evacuation failure that moves the affected regions into the old generation. Without any measure to reclaim these typically very quickly reclaimable regions as soon as the region has been unpinned, they can cause a significant buildup of old generation regions, resulting in more garbage collections and an unnecessary Full GC in the worst case.
Obviously this also helps with reclaiming space in evacuation failed regions caused by being unable to copy an object due to out-of-memory.
On another note this change removes the previous (self-imposed) limitation in G1 that only certain types of young collections could reclaim space in old generation regions. Now any young collection may evacuate old generation regions if they meet some requirements.
-
The long journey to remove the use of the
GCLockerin G1 is over, as JDK-8318706 has been integrated and the JEP 423: Region Pinning for G1 completed.In short, previously if an application accessed an array via the
Get/ReleasePrimitiveArrayCriticalmethods when interfacing with JNI, no garbage collection could occur. This change modifies the garbage collection algorithm to keep these objects in place, “pinning” them and marking the corresponding region as such, but allow evacuation of any other regions or non-primitive arrays within pinned regions. The latter optimization is possible becauseGet/ReleasePrimitiveArrayCriticalcan only lock primitive array objects.Now Java threads will never stall due to JNI code with G1.
-
There is some minor change in heap resizing during the Remark pause to make resizing a bit more consistent in JDK-8314573. Heap resizing now calculates the heap size change based on
-XX:Min/MaxHeapFreeRatiowithout taking Eden regions into account. As the Remark pause can happen at any time during the mutator phase, the previous behavior made the heap size changes very dependent on current Eden occupancy (i.e. how far into the mutator phase the application has been when the Remark pause occurs, the amount of free regions used for the calculation can differ a lot, resizing the heap differently).This results in more deterministic and generally less aggressive heap sizing.
-
This list is rounded out with an actual, direct performance improvement: a region’s code root set, i.e. the roots from compiled code, were previously handled by a single thread per region during garbage collection. In cases where the code root set is very unbalanced (lots of code having a embedded references into a single or few regions) this could cause this work stalling garbage collection. JDK-8315503 makes G1 distribute code root scan work across multiple threads even within regions, removing this potential bottleneck.
All STW GCs
- Loom necessitated the code cache sweeper to be removed in JDK-8290025. Its work has been, in case of the STW collectors, moved into the appropriate pause. Unfortunately a part of the code sweeper job had a component that has had a runtime of O(n^2) where n is the number of unloaded methods. This was not that big of an issue as long as the code sweeper did its work concurrent to the application, but after the removal caused significant pause time regressions when unloading a lot of compiled code. With JDK-8317809, JDK-8317007, JDK-8317677 and a few others class unloading in the pause is now actually faster than even before the code cache sweeper had been removed but still doing all the work.
What’s next
Work for JDK 23 has already started. Probably the most interesting upcoming change is the JEP Draft: Late G1 Barrier Expansion. From a GC point of view this makes barrier generation much more accessible to non-C2 expert developers to allow much easier tinkering.
Another interesting topic that may be tackled in the JDK 23 timeframe is further reducing class unloading time, both by improving the code but for G1 also moving out parts of it to the concurrent phase.
More to come in the next months :)
Thanks go to…
Everyone that contributed to another great JDK release. See you next release :)
Thomas