New Write Barriers for G1
The Garbage First (G1) collector’s throughput sometimes trails that of other HotSpot VM collectors - by up to 20% (e.g. JDK-8253230 or JDK-8132937). The difference is caused by G1’s principle to be a garbage collector that balances latency and throughput and tries to meet a pause time goal. A large part of that can be attributed to the synchronization of the garbage collector with the application necessary for correct operation. With JDK-8340827 we substantially redesign how this synchronization works for much less impact on throughput. This post explains these fairly fundamental changes.
Other sources with more information are the corresponding draft JEP and the implementation PR.
Background
G1 is an incremental garbage collector. During garbage collection, a large part of time can be spent on trying to find references to live objects in the areas of the application heap (just heap in the following) to evacuate them. The most simple and probably slowest way would be to look through (scan) the entire heap that is not going to be evacuated for such references. The stop-the-world Hotspot collectors, Serial, Parallel and G1 in principle employ a fairly old technique called Card Marking [Hölzle93] to limit the area to scan for references during the garbage collection pause.
In an attempt to better keep pause time goals, G1 extended this card marking mechanism:
- concurrent to the application, G1 re-examines (refines) the cards marked by the application and classifies them. This classification helps in the garbage collection pause to only need to scan cards important for a particular garbage collection.
- extra code compiled into the application (write barriers) remove unnecessary card marks, reducing the amount of cards to scan further.
This comes at additional cost as the next sections will show.
Card Marking in G1
Card Marking divides the heap into fixed-size chunks called cards. Every card is represented as a byte in a separate fixed-size array called a card table. Each entry corresponds to a small area, typically 512 bytes, in the heap. A card may either be marked or unmarked, a mark indicating the potential presence of interesting references in the heap corresponding to the card. An interesting reference for garbage collection is a reference that refers from an area in the heap that is not going to be garbage collected to one that is.
When the application modifies an object reference, additional code compiled into application, the write barrier, intercepts the modification and marks the corresponding card in the card table.
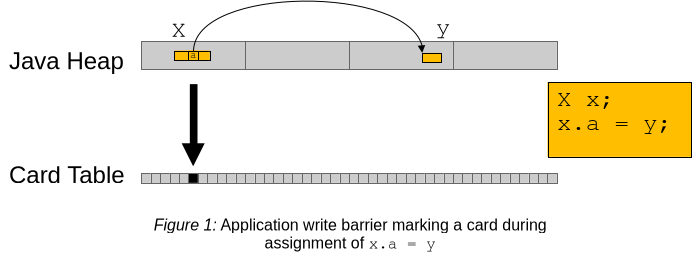
Figure 1 above shows an example execution of a hypothetical assignment of the field a in an object x of type X with a value of y. After writing the value into the field, the write barrier code (to be exact, post write barrier code, i.e. code added after setting the value) marks the card.
This is where the Serial and Parallel garbage collectors stop at: they let the application accumulate card marks until garbage collection occurs. At that time all of the heap corresponding to the marked cards is scanned for references into the evacuated area. In most applications this is okay effort-wise: the number of unique cards that need to be scanned during garbage collection is very limited. However, in other applications, scanning the heap corresponding to cards (scanning the cards) can take a very significant amount of total garbage collection time.
G1 tries to reduce this amount of card scanning in the garbage collection pause by several means. The first is using extra garbage collection threads running concurrent to the application clearing, re-examining and classifying card marks because:
- references are often written over and over again between garbage collections. A card mark caused by a reference write may, by the time the next garbage collection occurs, not contain any interesting reference anymore.
- by classifying card marks according to where they originate from, it is possible to only scan marked cards that are relevant for this particular garbage collection during the garbage collection.
Figure 2, 3 and 4 give details about this re-examination (refinement) process.
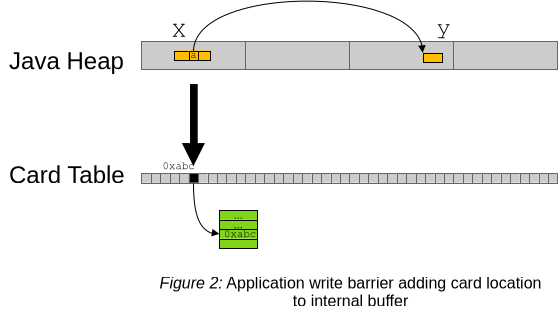
First, Figure 2 shows that in addition to the actual card mark mentioned above, the write barrier stores (enqueues) the card location (in this case 0xabc) in an internal buffer (refinement buffer) shown in green so that the re-examination garbage collector threads (refinement threads) can later easily find them again.
There is an artificial delay based on available time in the pause for scanning cards and the rate the application generates new marked cards between card mark and refinement. This delay helps decreasing the overhead of an application repeatedly marking the same cards, avoiding that the same cards will be repeatedly enqueued for refinement (as they are already marked). The delay also increases the probability that the references in the card itself are not interesting anymore.
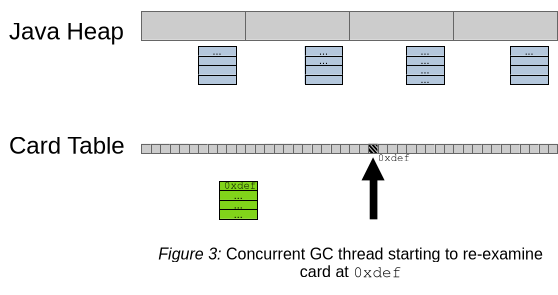
In the next step, shown in Figure 3, refinement threads will pick up previously enqueued cards for re-examination. In this example, the card at location 0xdef will be refined. The figure also shows the remembered sets in light blue: for every area to evacuate, G1 stores the set of interesting card locations for this area. In this figure every area has such a remembered set attached to it, but there may not be one currently for some. Areas may also be discontiguous in the heap (JDK-8343782 and JDK-8336086). The refinement thread also unmarks the card before looking at the corresponding contents of the heap.
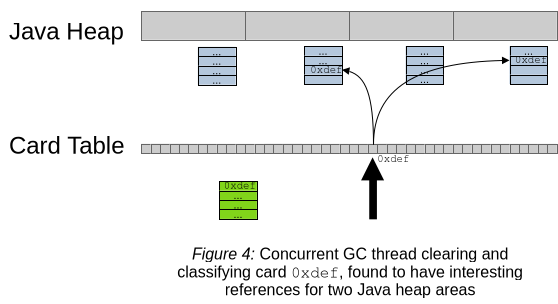
Finally, Figure 4 shows the step where the refinement threads put the examined card (0xdef) into the remembered sets of the areas for which that card contains an interesting reference at this point in time. Since the heap covered by a card may contain multiple interesting references, multiple remembered sets may receive that particular card location.
The end result of this fairly complicated process is that, compared to the other throughput collectors in the Hotspot VM, in the garbage collection pause G1 only needs to scan cards from two sources:
- cards just recently marked dirty by the application and not yet refined.
- cards from the remembered sets of areas that are about to be collected.
G1 will merge these two sources, marking cards from the remembered sets on the card table, before scanning the card table for card marks [JDK-8213108].
Depending on the application this can result in a significant reduction of time spent in card scanning during garbage collection compared to regular card marking.
Write Barrier in G1
Barriers are small pieces of code that are executed to coordinate between the application and the VM. Garbage collection extensively uses them to intercept changes in memory. The Serial, Parallel and G1 garbage collectors use, write barriers on writes to references, i.e. every time the application writes a value into a reference. The VM executes additional code the vicinity of that write.

The figure above visualizes this: for a write of the value y into a field x.a, next to the actual write, code unrelated to the write used for synchronization with the garbage collector is executed; Serial and Parallel GC only have a post-write barrier (after the write), while G1 has both pre- and post-write barriers (before and after the write). G1 uses the pre-write barrier for unrelated matters to this discussion, so the following text will just use “write barrier” or just “barrier”.
The previous section hinted at the responsibilities of the write barrier in G1:
- mark the card as dirty
- store the card location in refinement buffers if the card has not been marked yet
This sounds straightforward, but unfortunately there is some complication that Figure 5 shows: both the application and the refinement threads might write to the same card at the same time. The former marking it, the latter clearing it. This might result in lost updates to the remembered sets where the refinement thread would observe the card mark but not observe the write of the value without additional precautions. In fact, this requires some fairly costly memory synchronization in the write barrier.

Additionally, concurrent refinement of cards can be expensive, particularly if there are no extra processing resources available. So, the G1 barrier contains extra filtering code to avoid card marks that are generated by reference writes that make no difference for garbage collection.
The G1 write barrier will not mark a card if
- the reference assignment writes a reference that is not interesting, not crossing areas.
- the code assigns a
nullvalue: these do not generate links between objects, so the corresponding marked cards are unnecessary. - the card is already marked, which means that it is already scheduled for refinement.
Figure 6 compares the sizes of the resulting write barriers, the directly inlined part of the G1 write barrier (there is an additional part not shown here which is executed somewhat rarely) on the left with the whole Serial and Parallel GC write barrier on the right ([Protopopovs23]).

Without going into detail, instead of three (x86-64) instructions, the G1 write barrier takes around 50 instructions. The bars to the left of the G1 write barrier roughly correspond to above tasks: blue for the filters, green for the memory synchronization and the actual card mark, and orange for storing the card in the refinement buffers for the refinement threads
Impact
G1 uses a large write barrier with many mechanisms to minimize performance impact of the memory synchronization necessary for correctness and overhead of concurrent work.
All the effort to reduce memory synchronization is wasted if the application’s memory access pattern does not fit them and actually performs lots of fairly random reference assignments across the whole heap which to a large part result in enqueuing of many card locations for later refinement like BigRAMTester [JDK-8152438].
The other poor fit for this write barrier are applications that execute the write barrier in tight loops and at the same time extremely rarely generate a card mark with interesting references so that no concurrent refinement is necessary or actually ever performed (e.g. JDK-8253230). These are hampered by the large code footprint of the barrier, inhibiting compiler optimizations, or just execute slowly due to unnecessary allocation of CPU resources.
A New Approach
Previous sections showed that a large part of the G1 write barrier is required by the per-card mark memory synchronization to guarantee correctness in case of concurrent writes to the card table and storing the card locations for subsequent refinement.
To remove the memory synchronization, similar to ZGC’s double-buffered remembered sets [JEP439], this new approach uses two card tables. Each set of threads, the application threads and the refinement threads, gets assigned their own card table, each initially completely unmarked. Each set of threads only ever writes different values to their card table (just “card table” and “refinement table*” respectively in the following), obviating the need for fine-grained memory synchronization during actual card mark.
Similar to before there is a heuristic that tracks card mark rate on the application card table, and if the heuristic predicts that there will be too many card marks on that card table to meet pause time goal in the next garbage collection, G1 swaps the card tables atomically to the application. The application then continues to mark its card table (previously the refinement table), while garbage collection refinement threads work to re-examine all marks from the refinement table (the previous application card table).
This removes the need for memory synchronization in the G1 write barrier.
Additionally, the refinement table is directly used as storage for the to-be-refined marked cards, given that finding the marked cards is not prohibitively expensive.
This completely removes the need for the write barrier code to store the card locations in refinement buffers, and the memory synchronization.
New Card Marking in G1
Figure 7 shows this new arrangement of data structures: there are now two card tables, and the write barrier as before marks the card on the (application) card table.
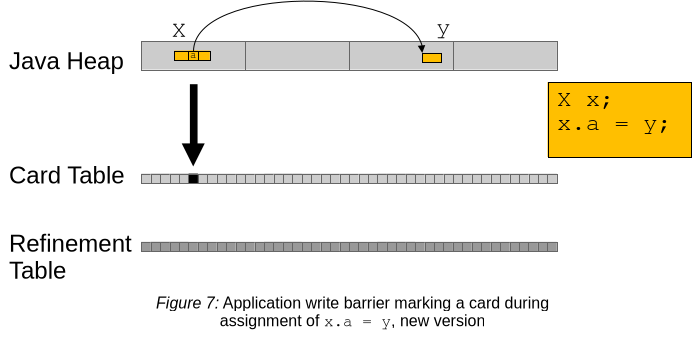
When the card table accrued enough marks, G1 switches card tables atomically. Figure 8 shows an example where the application card table and the refinement table were just switched, and the application already continued marking cards on the former refinement table.
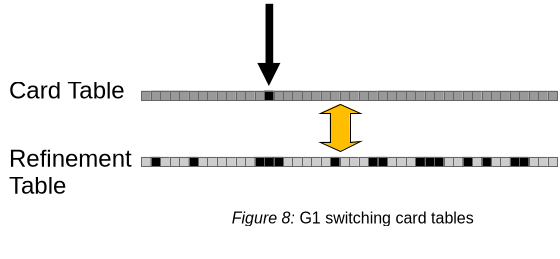
Refinement threads start re-examining cards from the refinement table (previously application card table) as before as described. Card marks are cleared until all marked cards have been processed. Since the application threads continue to mark cards on their card table, no synchronization between application threads and refinement threads is required.
New Write Barrier in G1
At minimum, the new G1 write barrier requires the card mark, similar to Parallel GC. The difference is that unlike in the Parallel GC write barrier, the card table base address is not constant as it changes every card table switch. So Parallel GC can inline the card table address into the code stream, G1 needs to reload it every time from thread local storage.
The final current post write barrier for G1 reduces to the filters and the actual card mark. For a given assignment x.a = y, the VM now adds the following pseudo-code after the assignment:
(1) if (region(x.a) == region(y)) goto done; // Ignore references within the same region/area
(2) if (y == nullptr) goto done; // Ignore null writes
(3) if (card(x.a) != Clean) goto done; // Ignore if the card is non-clean
(4)
(5) *card(x.a) = Dirty; // Mark the card
(6) done:
Line (1) to (3) implement the filters. They are almost the same as before, with a slightly different condition for the last filter due to an optimization.
Without the filters, there were some regressions compared to the original write barrier with the filters; the filters also decrease the number of cards that have not been scanned during the garbage collection pause, and the number of cards to be re-examined, so they were kept for now.
Finally, line (5) actually marks the card with a “Dirty” color value.
The original card marking paper uses two different values for card table entries, i.e. colors: “Marked” and “Unmarked”, or typically named “Dirty” and “Clean” in the Hotspot VM. In total G1 uses five colors which store some additional information about the corresponding heap area:
- clean - the card does not contain an interesting reference.
- dirty - the card may contain an interesting reference.
- already-scanned - used during garbage collection to indicate that this card has already been scanned. Necessary for the potentially staged approach of garbage collection to better keep pause time.
-
to-collection-set - the card may contain an interesting reference to the areas of the heap that are going to be collected in the next garbage collection (the collection set, hence the name). This collection set always contains the young generation because it is always collected at every garbage collection.
Refinement can skip scanning these cards because they will always be scanned later during garbage collection as G1 always collects the young generation. Adding these cards to remembered sets, even if they contained references to regions not in the collection set, is not needed either, they would actually represent duplicate information.
Effectively, the set of to-collection-set cards also store the entire remembered set for the next collection set on the card table, avoiding extra memory.
To keep the write barrier simple, it only colors cards as “Dirty”. The additional overhead determining whether a reference refers to an object in the collection set is too expensive here.
- from-remset - used during garbage collection to indicate that the origin of this card is a remembered set and not a recently marked card. This helps distinguishing cards from remembered sets from cards from not yet examined cards to more accurately model the application’s card marking rate used in heuristics.
Only the last two card colors are new. The use of the to-collection-set color explains the condition used in line (3) of the write barrier above: it avoids the application overwriting this value unnecessarily excluding benign races.
Switching the Card Tables and Refinement
The goal of the card table switching process is to make sure that all threads in the system agree on that the refinement table is now the application card table and the other way around to avoid the problematic situation described earlier in Figure 5.
The process is initiated by a special background thread, the refinement control thread. It regularly estimates whether the currently estimated number of cards at the start of the next garbage collection would exceed the allowed number of not re-examined cards given card examination rate. If refinement work is necessary, it also calculates the number of refinement worker threads, which do the actual work, needed to complete before the garbage collection.
This refinement round consists of the following phases:
-
Swap references to the card tables. This includes global card table pointers that newly created VM threads and VM runtime calls use, and every internal thread’s local copy of the current reference to the application card table. This step uses thread local handshakes (JEP 312) and a similar technique for VM internal, garbage collector related, threads.
This ensures correct memory visibility: After this step, the entire VM uses the previous refinement table to mark new cards, and all card marks and reference writes by the application at that point are synchronized.
-
Snapshot the heap to gather internal data about the refinement work. For every region of the heap the snapshot stores current examination progress. This allows resuming the refinement at any time and facilitates parallel work.
-
Re-examine (sweep) the refinement table containing the marked cards. Refinement worker threads walk the card table linearly (hence sweeping), claiming parts of it to look for marked cards using the heap snapshot.
As Figure 9 shows, the refinement threads re-examine marked cards, with the following potential results:
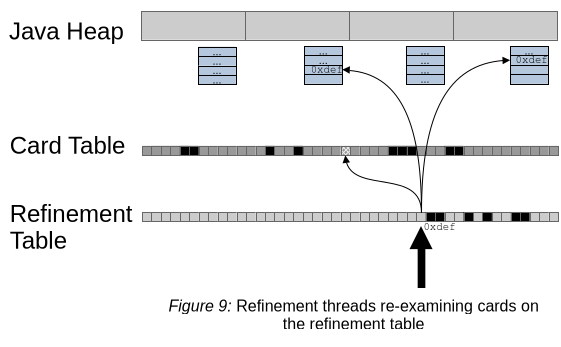
- Cards with references to the collection set are not added to any remembered set. The refinement thread marks these cards as to-collection-set in the application card table and skips any further refinement.
- If the card is marked as to-collection-set, the refinement thread will re-mark this card on the card table as such and not examine the corresponding heap contents at all.
- Dirty cards which correspond to the heap that can not be examined right now will be forwarded to the application card table as dirty.
- Interesting references in heap areas corresponding to dirty cards cause that card to be added to the remembered sets.
- During card examination, the card is always set to clean on the refinement table. Parts of the refinement table corresponding to the collection set are simply cleaned without re-examination as these cards are not necessary to keep. During evacuation of these regions, the references of live objects in this area will be found implicitly by the evacuation.
Writing directly to the application card table by the refinement threads is safe: memory races with the application are benign, the result will be at worst another dirty card mark without the additional to-collection-set color information.
-
Calculate statistics about the recent refinement and update predictors.
Any of these steps may be interrupted by a safepoint, which may be a garbage collection pause that evacuates memory. If not, the refinement worker threads will continue their refinement work using the heap snapshot where they left off.
Garbage Collection and Refinement
Refinement heuristics try to avoid having garbage collection interrupt refinement. In this case, the refinement table is completely unmarked at the start of the garbage collection, and all the not-yet examined marked cards are on the application card table, just where the following card table scan phase expects them. No further action except putting the remembered sets of areas to be collected on the application card table must be taken to be able to search for marked cards on the card table efficiently.
Previously G1 had information about the location of all marked cards, these locations were either recorded in the remembered sets, or in the refinement buffers to refine cards. Based on this, G1 could create a more detailed map of where marked cards were located, and only search those areas for marked cards instead of searching the whole card table. However, searching for marked cards is linear access to a relatively little area of memory, so very fast.
The absence of more precise location information for marked cards is also offset by not needing to calculate this information.
In the common case of garbage collections with only young generation heap areas to evacuate, there is nothing to do in this step as the young generation area’s remembered set is effectively tracked on the card table.
If a young garbage collection pause occurs at any point during the refinement process, the garbage collection needs to perform some compensating work for the not yet swept parts of the refinement table.
In this case the G1 garbage collector will execute a new Merge Refinement Table phase that performs a subset of the refinement process:
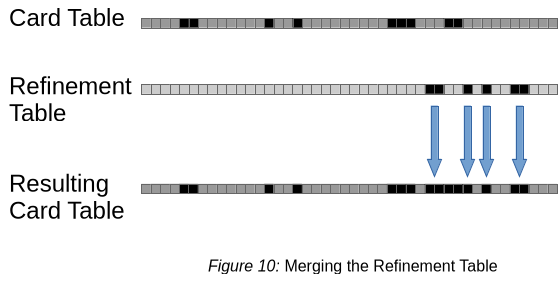
- (Optionally) Snapshot the heap as above, if the refinement had been interrupted in phase 1 of the process.
- Merge the refinement table into the card table. This step combines card marks from both card tables into the application card table. This is a logical or of both card tables. All marks on the refinement table are removed.
- Calculate statistics as above.
The reason why the refinement table needs to be completely unmarked at the start of the garbage collection is that G1 uses it to collect card marks containing interesting references for objects evacuated during the garbage collection in the heap areas the objects are evacuated to. This is similar to previously used extra refinement buffers to store those.
At the end of the young garbage collection, the two card tables are swapped so that all newly generated cards are on the application card table, and the refinement table is completely unmarked.
A full collection clears both card tables as this type of garbage collection does not need this information.
Performance Impact
This section contains some information about the aspects throughput, (native) memory footprint and latency compared to before these changes.
Throughput
In summary, throughput improves significantly
- for applications that execute the write barrier in full often because of the removal of the fine-grained synchronization in the barrier. Another aspect is that the new write barrier also significantly reduces refinement overhead because finding marked cards is faster (linear search vs. random access). There are also savings here due to reducing refinement work by keeping the young generation remembered set on the card table as these cards are at most re-examined once.
- the reduced CPU resource cost (size) of the write barrier enables better performance, either due to better optimization in the compiler or due to being easier to execute.
In G1, throughput improvements may manifest as reductions in used heap size.
The extent of the improvements can differ by microarchitecture. Parallel GC is still slightly ahead, there is more work going on reducing this difference further.
Native Memory Footprint
The additional card table takes 0.2% of Java heap size compared to JDK 21 and above. In JDK 21 one card table sized data structure has been removed, so JDKs before that do not show that difference.
Some of that additional memory is offset by removal of the refinement buffers for card locations. Additionally, memory usage is reduced by keeping the collection set’s remembered set on the card table, taking no extra space.
The optimization to color these remembered set entries specially keeps duplicates from appearing in the other remembered sets, also reducing native memory.
In some applications these memory reductions completely offset the additional card table memory usage, but this is fairly rare. Particularly applications that did not have large remembered sets for the young generation, which are mostly very throughput-oriented applications, show the above mentioned additional memory usage.
The refinement table is only required if the application needs to do any refinement. So, the refinement table could be allocated lazily, i.e. only if there is some refinement. There is a large overlap between such applications and above very throughput-oriented applications. This is not implemented in the current version.
Latency, Pause Times
Pause times are not affected, if not tending to be slightly faster. Pause times typically decrease due to a shorter “Merge remembered sets” phase because there is no work to do for the remembered sets for the young generation in the common case - they are always already on the card table.
Even if the refinement table needs to be merged into the card table it is extremely fast and is always faster than merging remembered sets for the young gen in my measurements. This work is linearly scanning some memory instead of many random writes, so this is embarassingly parallel.
The cards created during garbage collection do not need to be redirtied, so another garbage collection phase that was removed.
Code Size
During review a colleague mentioned that the change reduces total code size by around 5%.
Summary
This change removes the need for a large part of G1’s write barrier using a dual card table approach to avoid fine-grained synchronization, increasing throughput significantly for some applications.
Overall, I’m quite satisfied with the change - after many years thinking about and prototyping solutions to the problem without introducing some “G1 throughput mode” that would have huge implications on maintainability (basically another garbage collector) or making G1 unnecessarily complex this seems a very good solution, taking the advantages of these throughput barriers without too many drawbacks.
A lot of people helped with this change, my thanks.
Hth,
Thomas