JDK 23 G1/Parallel/Serial GC changes
Given that JDK 23 is in rampdown phase 2 this post is going to present you the usual brief look on changes to the stop-the-world collectors in OpenJDK.
Compared to the previous release JDK 23 is a fairly muted one in the GC area, but there are good things on the horizon that I will touch on at the end of this post :)
The full list of changes for the entire Hotspot GC subcomponent for JDK 23 is here, showing around 230 changes in total being resolved or closed at the time of writing. Nothing particular unusual here.
Parallel GC
-
The probably largest change to Parallel GC for some time has been the replacement of the existing Parallel GC Full GC algorithm with a more traditional parallel Mark-Sweep-Compact algorithm.
The original algorithm overwrites object headers during compaction, i.e. object movement, but still needs object sizes to (re-)calculate the final position of moved objects to update references. To enable that even in the presence of overwritten objects, Parallel GC Full GC stored the location where live objects end in a bitmap of the same size as the one that records live object starts during its first phase. Then, when needing an object size for a given live object, the algorithm scans forward from that object’s start in the end bitmap, looking for the next set bit and subtracts the former from the latter. This can be slow, and needs to be done every time as part of looking up the final position of moved objects. That is actually quadratic in the number of live objects as rediscovered in JDK-8320165, and although there were several related (JDK-8145318) and less related improvements targeted to this issue, this could not completely mitigate the problem as JDK-8320165 shows.
With JDK-8329203 we replaced the somewhat unique algorithm of Parallel GC with (basically) G1’s parallel Full GC which does not suffer from these hiccups. At the same time that second end bitmap (taking 1.5% of Java heap size) could be removed as well, while our measurements showed that overall the performance stayed the same (and improved a lot in these problematic cases).
-
Another performance bump in Parallel Full GC could be achieved by decreasing contention on the counters recording the number of live bytes per region: instead of every thread updating global counters immediately, with JDK-8325553 Parallel GC has every thread locally record per-region liveness as long as that thread only encountered live objects within the same (small set of) regions.
Serial GC
- Cleanup and refactoring of Serial GC code continued.
G1 GC
-
One of the more long-standing issues that got resolved in JDK 23 has been JDK-8280087 where G1 did not expand some internal buffer used during reference processing as it should. Instead it prematurely exited with an unhelpful error message.
-
Performance improvements like JDK-8327452 and JDK-8331048 improve pause times and reduce native memory overhead of the G1 collector.
All (STW) GCs
Some time ago we introduced dedicated (internal) filler objects which I wrote about here. The community pointed out that jdk.vm.internal.FillerArray is not a valid array class name, and some tools somewhat rightfully choke on such “variable sized regular” objects.
With JDK-8319548 the class name of filler arrays has been changed to [Ljdk/internal/vm/FillerElement; to conform to that, and backported to JDK 21 and above.
What’s next
Reduction of G1 remembered set storage requirements is still a very important topic to us: one old idea is to use a single rememebered set for multiple regions, removing the need to store remembered set entries within the group of regions with the same remembered set.
The figures below show the principle: Currently regions (the big rounded boxes at the top, with “Y” for “Young region” and “O” for “Old region”) may have remembered sets associated to them (the vertical small boxes below the regions). The entries refer to approximate locations (areas) outside of the respective region, where there may be a reference into that region.
Young regions always have remembered sets associated with them, as they are required to find references into these regions that need to be fixed up when moving a live object within them, and they are evacuated/moved at every garbage collection. You might notice that remembered set entries of different regions refer to the same locations in the old generation regions.
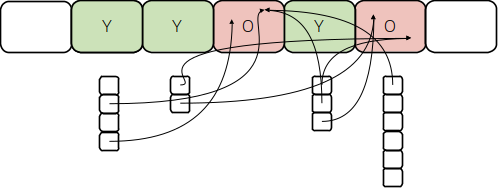
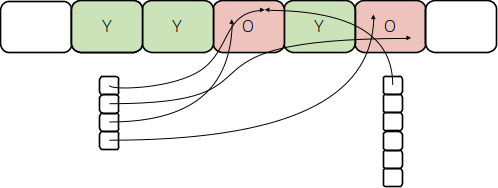
Now, as mentioned, particularly young generation regions are always evacuated at the same time, together, which means that all these remembered set entries that refer to the same locations are redundant. This is what the initial change to implement above idea does: use a single remembered set for all young generation regions, as depicted below, automatically removing the redundant remembered set entries. This not only saves memory, but also time during garbage collection to filter out these entries.
(Technically, combining remembered sets also removes the need for storing remembered set entries that refer to locations between regions in a group; however, for young generation regions no such remembered set entries will ever be generated so they are not shown and do not add to savings).
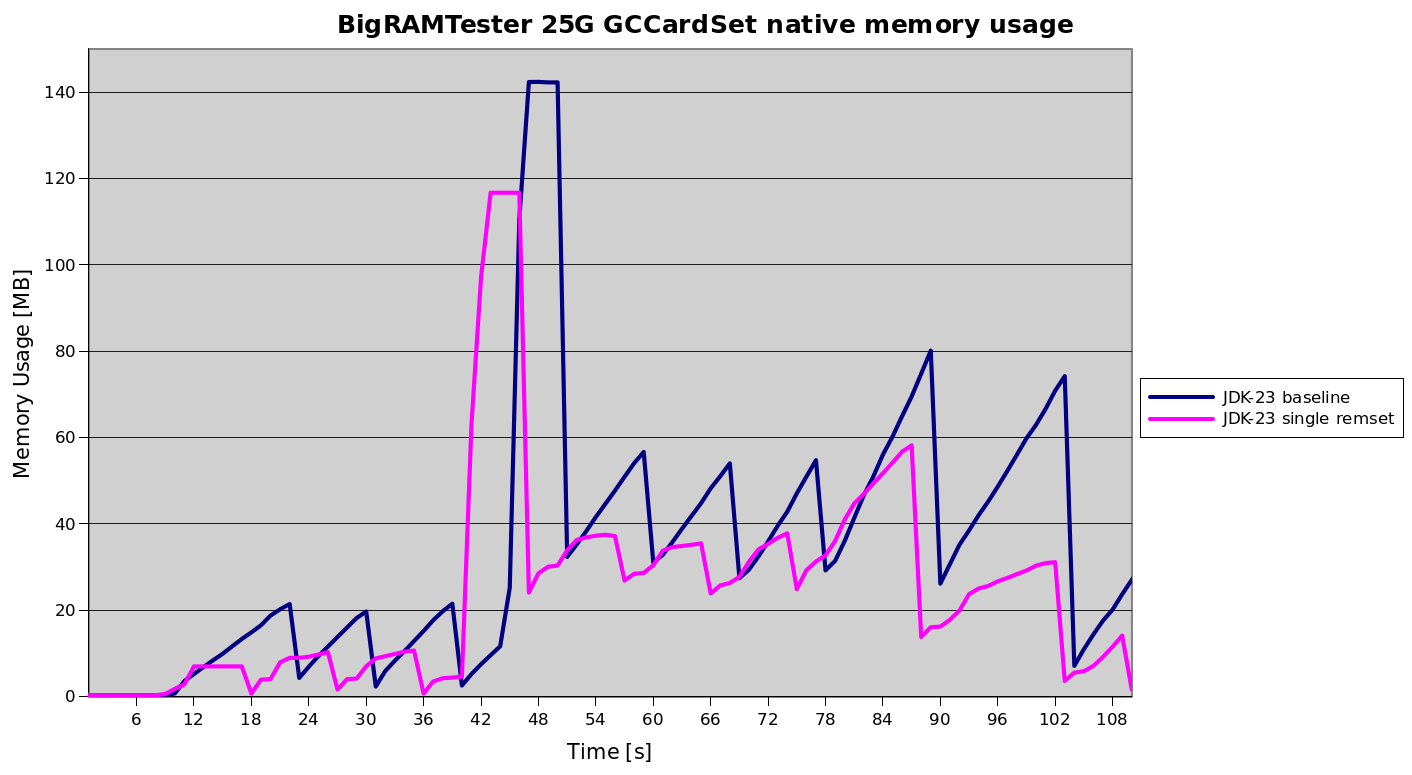
The gain for applying this technique for the young generation remembered sets only can already be substantial as shown below in some measurements of some larger application. The graph depicts remembered set memory usage before (blue line) and after (pink line) applying the change. Of particular note is the halving of memory usage for the remembered set in the first 40 seconds where only young generation regions have remembered sets.
As old generation regions get remembered sets assigned to them, the improvement decreases in that prototype due to lack of support for merging old generation regions, but the impact of just young generation region rememembered set savings are still noticeable.
This initial change for combining young generation region remembered sets is actually out for review, but a more generic variant to also merge old generation regions into groups using a single remembered set is in preparation.
In this release cycle another fairly large focus for improvements to the G1 collector have been changes to the write barriers: we spent a lot of effort to investigate how to best close the throughput gap of the G1 collector to Parallel GC in some cases (e.g. here and the differences reported here), and we believe we found very good solutions without compromising the latency aspect of the G1 collector.
One step in that direction is JEP 475: Late Barrier Expansion for G1 which seems to be on track for JDK 24 inclusion. It enables some of the optimizations we are planning.
There are still some details and kinks to work out, and it will take some time to do so, and even more time to have everything in place, but more to come in the next months…
Thanks go to…
… as usual to everyone that contributed to another great JDK release. Looking forward to see you next release.
Thomas